Starting out with pdpipe
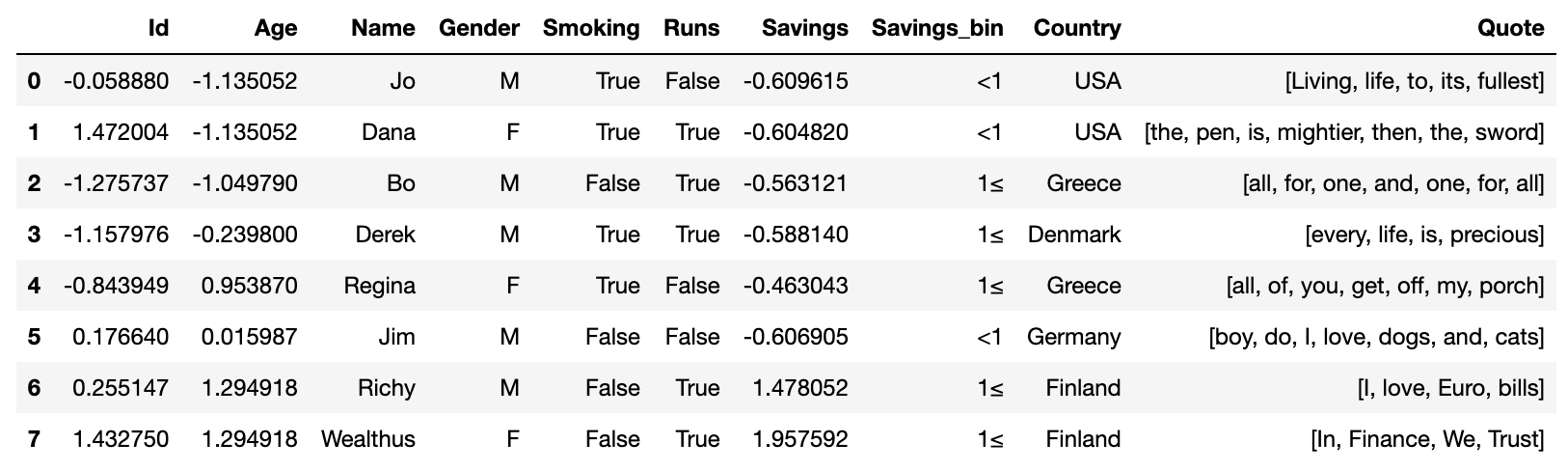
So how does using pdpipe looks like? Let's first import pandas and pdpipe, an intialize a nice little dataframe:
import pandas as pd
raw_df = pd.DataFrame(
data=[
[42, 23, 'Jo', 'M', True, False, 0.07, 'USA', 'Living life to its fullest'],
[81, 23, 'Dana', 'F', True, True, 0.3, 'USA', 'the pen is mightier then the sword'],
[11, 25, 'Bo', 'M', False, True, 2.3, 'Greece', 'all for one and one for all'],
[14, 44, 'Derek', 'M', True, True, 1.1, 'Denmark', 'every life is precious'],
[22, 72, 'Regina', 'F', True, False, 7.1, 'Greece', 'all of you get off my porch'],
[48, 50, 'Jim', 'M', False, False, 0.2, 'Germany', 'boy do I love dogs and cats'],
[50, 80, 'Richy', 'M', False, True, 100.2, 'Finland', 'I love Euro bills'],
[80, 80, 'Wealthus', 'F', False, True, 123.2, 'Finland', 'In Finance We Trust'],
],
columns=['Id', 'Age', 'Name', 'Gender', 'Smoking', 'Runs', 'Savings', 'Country', 'Quote'],
)
This results in the following dataframe:
Constructing pipelines
We can create different pipeline stage object by calling their constructors,
which can be of course identified by their camel-cased names, such as
pdp.ColDrop for dropping columns and pdp.Encode to encode them, etc.
To build a pipeline, we will usually call the PdPipeline class constructor,
and provide it with a list of pipeline stage objects:
import pdpipe as pdp
from pdpipe import df
pipeline = pdp.PdPipeline([
df.set_index('Id'),
pdp.ColDrop('Name'),
df.drop_rows_where['Savings'] > 100,
df['Healthy'] << df['Runs'] & ~df['Smoking'],
pdp.Bin({'Savings': [1]}, drop=False),
pdp.Scale('StandardScaler'),
pdp.TokenizeText('Quote'),
pdp.SnowballStem('EnglishStemmer', columns=['Quote']),
pdp.RemoveStopwords('English', 'Quote'),
pdp.Encode('Gender'),
pdp.OneHotEncode('Country'),
])
pdpipe's df handle
pdpipe has a powerful handle named df, which can be used in several ways:
-
Creating column assignment pipeline stages that use series-level operators and functions, such as with
df['c'] << df['a'] + df['b'].map({1: 3, 2:4}). -
Create pipeline stages from
panads.DataFramemethods that represent dataframe-to-dataframe transforms, such asset_index,fillna,rename, etc. - Use custom fly handles such as
drop_rows_whereandkeep_rows where, such as with(df.drop_rows_where['a'] < 4) & (df.drop_rows_where['b'] >12).
Chaining constructor syntax
pdpipe also has a chaining syntax that you can use to construct pipelines
with characteristic one-liners (although admittedly, it is mainly
convenient for the creation of simple, short pipelines, in dynamic Python
shells):
pipeline = pdp.ColDrop('Name').RowDrop({'Savings': lambda x: x > 100}) \
.Bin({'Savings': [1]}, drop=False).Scale('StandardScaler') \
.TokenizeText('Quote').SnowballStem('EnglishStemmer', columns=['Quote']) \
.RemoveStopwords('English', 'Quote').Encode('Gender').OneHotEncode('Country')
Note: All pipeline stage constructors are available in this way, but
some advanced handles such as df, and fly handles such as
drop_rows_where, are not available through this syntax.
Printing the pipeline object displays it in order.
A pdpipe pipeline:
[ 0] Apply dataframe method set_index with kwargs {}
[ 1] Drop columns Name
[ 2] Drop rows by qualifier <RowQualifier: Qualify rows with df[Savings] > 100>
[ 3] Assign column Healthy with df[Runs] & ~df[Smoking]
[ 4] Bin Savings by [1].
[ 5] Scale columns Columns of dtypes <class 'numpy.number'>
[ 6] Tokenize Quote
[ 7] Stemming tokens in Quote...
[ 8] Remove stopwords from Quote
[ 9] Encode Gender
[10] One-hot encode Country
Pipeline slicing
The numbers presented in square brackets are the indices of the
corresponding pipeline stages, and they can be used to retrieve either the
specific pipeline stage objects composing the pipeline, e.g. with
pipeline[5], or sub-pipelines composed of sub-sequences of
the pipeline, e.g. with pipeline[2:6].
Applying pipelines
The pipeline can now be applied to an input dataframe using the apply
method. We will also provide the verbose keyword with True to show
informative prints and the progress of dataframe processing, stage by stage:
- set_index: Apply dataframe method set_index with kwargs {}
- Drop columns Name
- Drop rows by qualifier <RowQualifier: Qualify rows with df[Savings] > 100>
2 rows dropped.
- Assign column Healthy with df[Runs] & ~df[Smoking]
- Bin Savings by [1].
Savings: 100%|██████████████████████████████████| 1/1 [00:00<00:00, 158.35it/s]
- Scale columns Columns of dtypes <class 'numpy.number'>
- Tokenize Quote
- Stemming tokens in Quote...
- Remove stopwords from Quote
- Encode Gender
100%|█████████████████████████████████████| 1/1 [00:00<00:00, 297.36it/s]
- One-hot encode Country
Country: 100%|█████████████████████████████████████| 1/1 [00:00<00:00, 240.78it/s]
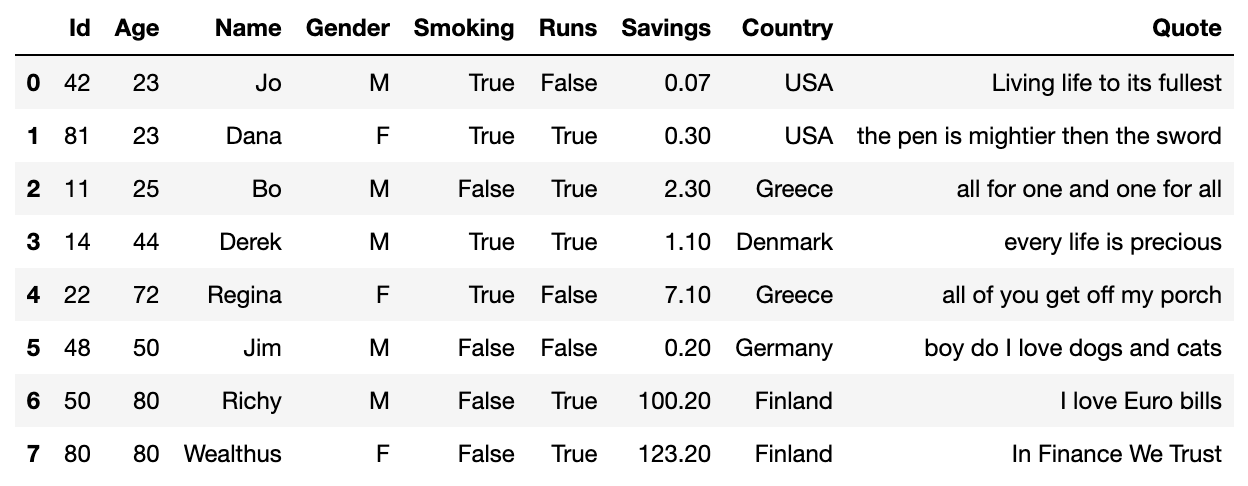
We will thus get the dataframe below. We can see all numerical columns were scaled, the Country column was one-hot-encoded, Savings also got a binned version and the textual Quote column underwent some word-level manipulations:
Fit and transform
Pipelines are also callable objects themselves, so calling pipeline(df) is
equivalent to calling pipeline.apply(df).
Additionally, pipelines inherently have a fit state. If none of the stages
composing them is fittable in nature this doesn't make a lot of a difference,
but many stage have a fit_transform vs transform logic, like encoders,
scalers and so forth.
apply() vs fit_transform()
The apply pipeline method uses either fit_transform and transform
in an intelligent and sensible way: If the pipeline is not fitted, calling
it is equivalent to calling fit_transform, while if it is fitted, the
call is practically a transform call.
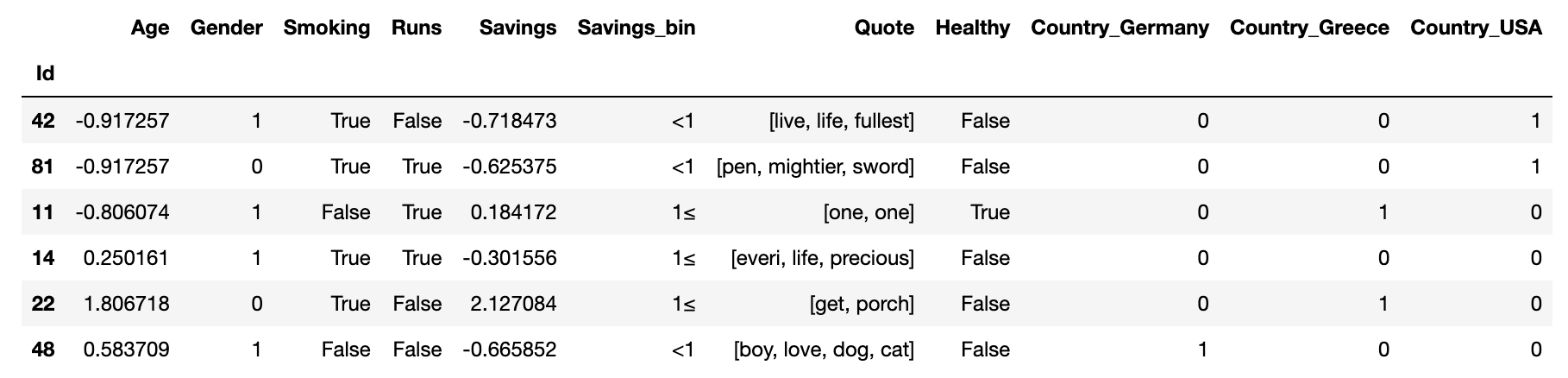
Let's say we want to utilize pdpipe's powerful slicing syntax to apply only
some of the pipeline stages to the raw dataframe. We will now use the
fit_transform method of the pipeline itself to force all encompassed pipeline
stages to fit-transform themselves:
Here, we will use pipeline[4:7] to apply the binning, scaling and
tokenization stages only: